汉字转拼音的浏览器端实现
背景介绍
汉字转拼音,首先想到的是准备一张超大的汉字到拼音的映射表,我们先来算下这张映射表有多大。
基本汉字一共有 20902 个,对应 Unicode 的编码范围是 4E00-9FA5,其中包括了朝鲜文汉字和日文汉字,所以也称为中日韩统一表意文字(英语:CJK Unified Ideographs)。有些汉字是多音字,如果每个汉字只取一种读音,这张汉字到拼音的映射表有 329KB,按拼音排序后,gzip 后的文件大小,最小可以减少至 46.7KB(不排序的话有 72.4KB,压缩算法对有序字符串有更高的压缩率)。所以,在浏览器中直接使用这个映射表文件的成本比较大,一般汉字转拼音都在后端处理。
今天向大家介绍一种在浏览器端实现的汉字转拼音方法,实现文件 gzip 后只有 2.7KB(修正 Safari 浏览器后的大小是 3.9KB),支持所有的基本汉字(实现时去掉了浏览器不识别的汉字,比如在 Chrome 浏览器中去掉的汉字有:兙、兡、嗧、桛、烪、瓧、瓰、瓱、瓼、甅),体积和效率都有保证。
注意,本实现不支持多音字,也不支持声调。在浏览器端使用的时候,由于输入法一般也打不出声调来,所以使用场景应该不受影响。另外映射表和代码也可以自己实现,以便满足个性化需求。
实现原理
在 JavaScript 中,字符串 String 有个方法叫 localeCompare,它可以对汉字按拼音进行排序,代码如下:
let name = '网易杭州';
let sortedName = name.split('').sort((a, b) => {
// 如果我没记错的话,早期的这个方法并不需要第二个参数
return a.localeCompare(b, 'zh-CN');
}).join('');
console.log(sortedName); // 输出 '杭网易州'该方法在 Chrome、Safari、Firefox、IE11 等浏览器中都可以使用。利用这个方法,就可以知道任意两个汉字的相对顺序。
汉字虽然有 20000 多个,但汉字拼音是有限的,一共有 410 多个拼音,这些拼音把所有的汉字划分成了一个个的区块:
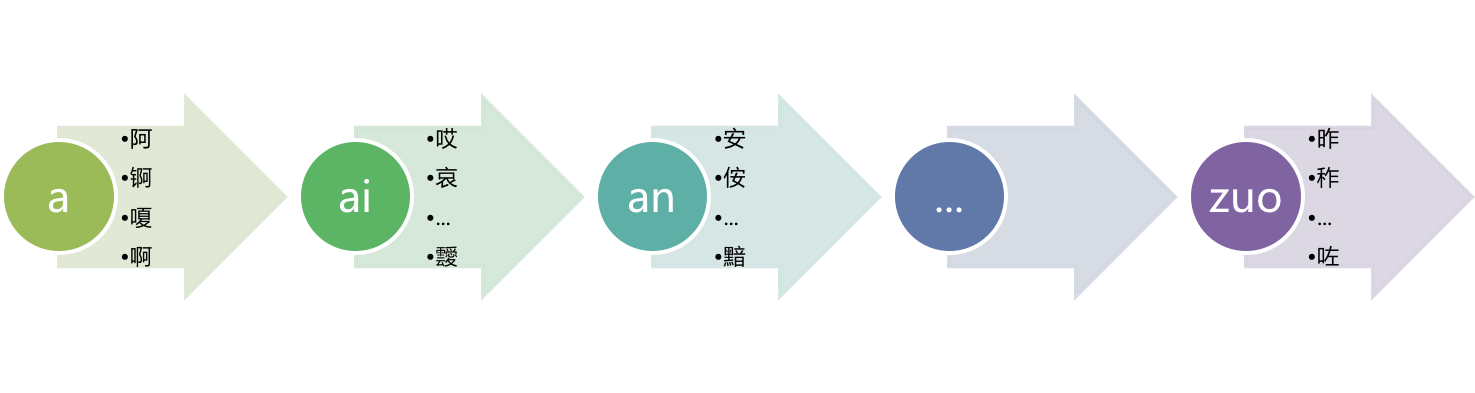
每一个汉字,它都会落在上图的某个区块中。我们取每个拼音第一个出现的汉字:
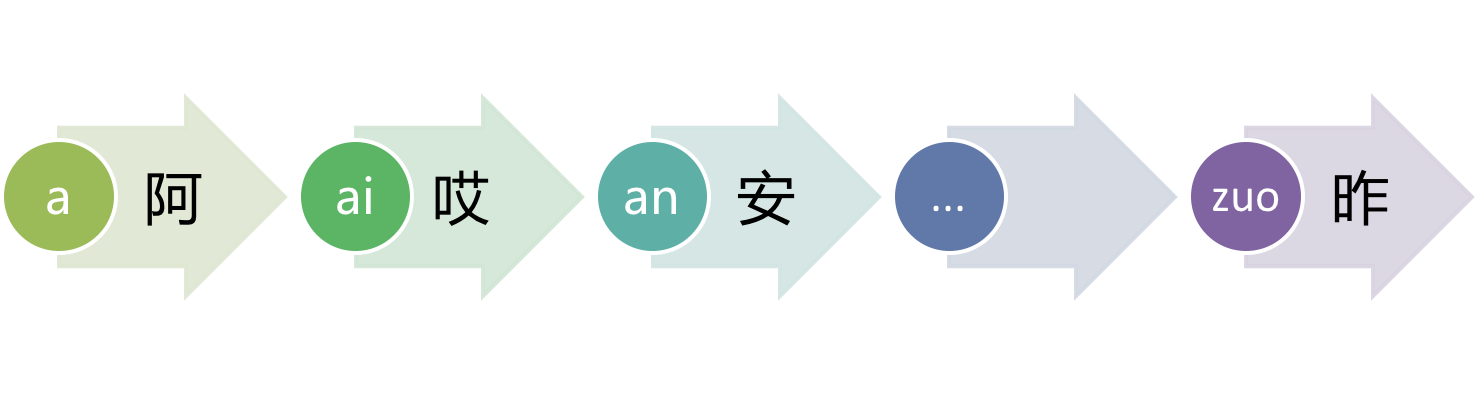
我们的目的是计算汉字的拼音,将目标汉字与上图的每个汉字使用 localeCompare 方法进行比较,每次比较就只有三种结果,要么在被比较汉字的前面,要么在被比较汉字的后面,还有一种情况是正好和被比较汉字相同,通过一轮比较,我们就可以得知目标汉字落在了哪个区块,而该区块对应的拼音是事先准备好的,所以也就得到了目标汉字对应的拼音。因为上图组成的汉字列表,是按拼音排序的,也就是它是一个有序列表,那么就可以使用二分查找法,快速地进行定位。二分查找的时间复杂度是 O(log n),410 个拼音,最多比较 9 次,效率有了保证。
我们举个具体的例子,假设目标汉字为“哀”,通过比较我们发现它排在“哎”后面,排在“安”前面,“安”是“an”的第一个拼音汉字(每种拼音相同的汉字可能有很多个,第一个拼音汉字,本文是指每种拼音第一个出现的汉字),它前面肯定是“ai”区块(如果不取第一个拼音汉字,这种情况还是无法确定目标汉字到底是在“ai”区块还是在“a”区块,因为每个区块有 N 个汉字,这些汉字本身也有相对顺序;当然,我们也可以取最后一个拼音汉字作为比较汉字),所以“哀”的拼音肯定是“ai”了。
实现原理就这么简单,非常巧妙。下面介绍如何得到这张汉字拼音映射表。
汉字拼音映射表
看到这里,有同学可能会说这还不简单,找本《现代汉语词典》就行了,但这种手工方式,保守估计也要花 1 天时间的工作量,效率低下姑且不说,毕竟这是一次性劳动,最要命的是,有些汉字在《现代汉语词典》的顺序和在浏览器中的顺序是不一样的。
既然我们已经知道了汉字的 Unicode 编码范围,只要一个循环,就能得到所有的汉字,再调用提供汉字到拼音转换的第三方 API 接口(比如这个网站:中文转拼音,每次可以转换 3000 个汉字),这样就能很快得到所有汉字以及对应拼音的映射表。再利用 localeCompare 方法,对这张表的汉字排序,这样就能得到有序的所有汉字拼音表。由于我们只取每种拼音的第一个汉字,再写段很简单的代码就可以提取出来了。
下面这段获取所有汉字及相应拼音的示例代码,可以在 Chrome 插件中(在插件中接口可以跨域调用)运行得到结果:
let start = 0x4e00, end = 0x9FA5;
let result = {};
let get = function () {
if (start > end) {
// 此时 result 就包含了所有的汉字以及相应的拼音
console.log(JSON.stringify(result));
return;
}
let arr = []
for (let i = start; i < start + 3000; i++) {
if (i <= end) {
arr.push(String.fromCharCode(i))
}
}
let xhr = new XMLHttpRequest();
let fd = new FormData();
fd.append('zwzyp_zhongwen', arr.join(''));
fd.append('zwzyp_shengdiao', 0);
fd.append('zwzyp_wenzi', 1);
fd.append('zwzyp_jiange', 1);
fd.append('zwzyp_duozhongduyin', 0);
xhr.onload = function (evt) {
let div = document.createElement('div')
div.innerHTML = evt.target.responseText;
let pinyins = div.querySelectorAll('.xiaokuang_py');
let hanzis = div.querySelectorAll('.xiaokuang_z');
for(let i = 0; i < hanzis.length; i++) {
result[hanzis[i].innerHTML] = pinyins[i].innerHTML;
}
start += 3000;
get();
}
xhr.open('POST','https://zhongwenzhuanpinyin.51240.com/web_system/51240_com_www/system/file/zhongwenzhuanpinyin/data/');
xhr.send(fd);
}
get();以上代码获取到的结果,有些汉字的拼音并不正确,有些汉字没有给出拼音,这些问题我暂时也没想到很好的解决方案,要么换转换源,要么手工修正。
修正之后,我们在浏览器中再对这些汉字进行按拼音排序,排序的结果是需要遵守的,所以如果汉字出现在了它不该出现的位置(也就是说浏览器给出的结果并不正确),那对这些汉字需要特殊处理,只要用一个 Map 对象,它包含所有不正确的汉字即可。
比如“芎”这个字,Chrome 浏览器把它排在了“qiong”这个区块中,其实它应该念“xiong”。除了这些浏览器误读的汉字,我们还可以修正一些多音字的问题,比如“沈”,浏览器把它排在了“chen”这个区块,但一般这个字念“shen”,这种就可以按照自己的需求处理了。还有比如“谁”,浏览器把它排在了“shei”区块,但我们一般念“shui”,这个字更加特殊,因为只有这么一个字念“shei”,所以可以把“shei”这个读音从映射表中删除,从理论上减少比对时的查找次数。
在 Chrome 浏览器中,有以下汉字需要特殊处理:
// 此表可以根据自身需求进行删减
let fixedHanzis = {
'沈': 'shen', '嗲': 'dia', '碡': 'zhou', '聒': 'guo', '炔': 'que',
'蚵': 'ke', '砉': 'hua', '嬤': 'mo', '蹒': 'pan', '丬': 'pan', '霰': 'xian',
'豉': 'chi', '饧': 'xing', '帧': 'zhen', '郍': 'na', '芎': 'xiong', '谁': 'shui'
}兼容 Chrome 和 Safari 的汉字拼音映射表
在不同的浏览器中,通过 localeCompare 方法得到的汉字顺序并不一样,Safari 和 Chrome 有较大差异,如果映射表要同时适用这两个浏览器,需要根据实际情况再次修正。我建议以 Chrome 浏览器为准,因为 Safari 中的误读情况比较多。
如果误读的不是第一个拼音汉字,则把它加入特殊修正映射表(本文使用 fixedHanzis 对象指代,下同)中就可以了。如果误读的正好是第一个拼音汉字,则修正时要具体问题具体分析,修正情况如下:
可以在 Chrome 和 Safari 中先把所有第一个拼音的汉字用代码找出来,然后人工挨个对比,貌似也没有很好的方法
| 拼音 | Safari | Chrome | 修正方案 | 说明 |
|---|---|---|---|---|
| ba | 八 | 丷 | 丷 -> 八,丷 -> fixedHanzis | 由于“丷”是一个不常用汉字,也可以直接忽略,即映射表中直接使用“八” |
| chou | 婤 | 抽 | 抽 -> 婤 | |
| cou | 腠 | 凑 | 凑 -> 腠 | |
| dia | 嗲 | / | 无需修正 | Chrome 中这个字误读成了“die”,特殊修正映射表中已经有了“嗲” |
| du | 艔 | 厾 | 艔 -> fixedHanzis | Safari 也是误读 |
| fu | 伕 | 夫 | 夫 -> 伕 | |
| gou | 佝 | 勾 | 勾 -> 佝 | |
| hu | 乯 | 乎 | 乎 -> 乯 | |
| huan | 犿 | 欢 | 欢 -> 犿 | |
| li | 刕 | 哩 | 哩 -> 刕 | |
| lie | 列 | 毟 | 毟 -> 列 | |
| ling | 刢 | 伶 | 伶 -> 刢 | |
| me | 么 | 嚒 | 嚒 -> 么 | |
| men | 门 | 椚 | 门 -> 椚 | |
| meng | 甿 | 擝 | 擝 -> 甿 | |
| niang | 嬢 | 娘 | 娘 -> 嬢 | |
| pou | 娝 | 剖 | 剖 -> 娝 | |
| qie | 癿 | 苆 | 苆 -> 癿 | |
| qiong | 匔 | 卭 | 匔-> fixedHanzis | Safari 也是误读 |
| quan | 峑 | 奍 | 奍 -> 峑 | |
| sou | 捜 | 凁 | 凁 -> 捜 | |
| tou | 偸 | 偷 | 偷 -> 偸 | |
| wa | 穵 | 屲 | 屲 -> 穵 | |
| xian | 仚 | 仙 | 仙 -> 仚 | |
| you | 攸 | 优 | 优 -> 攸 | |
| yu | 扜 | 込 | 込 -> 扜 | |
| zhai | 捚 | 夈 | 夈 -> 捚 | |
| zhan | 沾 | 枬 | 枬 -> 沾 | |
| zheng | 争 | 凧 | 凧 -> 争 | |
| zhou | 诌 | 州 | 州 -> 诌 |
修复以上对比汉字后,Safari 还需要修复将近 180个读音有误的汉字,在 Safari 浏览器中需要将所有这些误读的汉字加入特殊修正映射表 fixedHanzis 中。
其他宿主环境
如果在其他宿主环境中也需要使用本方案,很可能会有出错的情况,修复方式同 Safari,不再赘述。
注:Firefox 和 Chrome 的表现完全一致,在 Node.js 中推荐使用完整的字典库。
具体实现
在具体实现的时候,如果使用 localeCompare,会发现它的效率很低,在 Chrome 浏览器中特别低,可以使用 Intl.Collator 这个对象。查找 20892 个汉字的拼音所要花费的时间如下(单位毫秒):
| 方法 | Safari | Chrome | Firefox |
|---|---|---|---|
| localeCompare | 3707 | 14030 | 2521 |
| Intl.Collator | 103 | 252 | 79 |
var COLLATOR = new Intl.Collator(['zh-CN'])
COLLATOR.compare('网', '易') // 输出 -1具体实现代码已托管在 github 上面:pinyin.js。
应用场景
看到这里,有同学可能会有疑问,汉字转拼音,在浏览器端有什么应用场景?
其实可以反过来使用。比如在 NEI 接口管理平台 网站中,在项目的接口列表页面有个搜索功能,可以按照用户输入的拼音在前端搜索。接口列表是一次性全部加载的,此时就可以先把相关内容转换成拼音,然后和用户输入的拼音进行对比即可。
吐槽
我们已经发现,在 Chrome 和 Safari 中,很多汉字的拼音是不对的,这里也吐槽一下中文语言包的制作者,我分析了下,大概有这么几种情况:
- 有些多音字选择了不常见的读音,比如“沈”,在 Chrome 中是“chen”,而不是常见的“shen”,又比如“呵”,在 Safari 中念“a”
- 读字读半边,这种例子有很多,比如“碡”,念成了“du”(正确的读音是 zhóu),“聒”念成了“gua”(正确的读音是 guō)
- 纯粹乱读,Safari 中有很多,比如“鼰”,念成了“nian”(正确的读音是 jú),“罉”,念成了“cang”(正确的读音是 chēng),“伝”,念成了“chuan”(正确的读音是 yún),“枡”,念成了“dou”(正确的读音是 shēng)
根据从上面的分析,我猜测一下:Chrome 的中文语言包制作者应该是一位在国外长大的中国人,Safari 的中文语言包制作应该是一位主修中文专业的外国人。还有一种可能是这两位同学都买到了一本假的汉语词典,并且,Safari 的这位同学是从街边小摊买的。
最后
文章就写到这里,最后发个广告,网易杭研长期求资深前端,欢迎简历。
参考资料
- 本方案并非原创,而是参考了 https://github.com/creeperyang/pinyin/ 的实现,并在它的基础做了一点微小的工作。如文中所说,该方案是从 Android 源码中扒出来的。
留下评论